Attention机制
本文最后更新于:2021年1月8日 晚上
When I’m translating a sentence, I pay special attention to the word I’m presently translating. When I’m transcribing an audio recording, I listen carefully to the segment I’m actively writing down. And if you ask me to describe the room I’m sitting in, I’ll glance around at the objects I’m describing as I do so.
当我正在翻译一句话时,我会特别注意我正在翻译的单词;当我正在录制一段录音时,我会仔细听我正在写下的片段。如果你要我描述我目前所在的房间,我会瞥一眼我将要描述的各种东西。
Neural networks can achieve this same behavior using attention, focusing on part of a subset of the information they’re given. For example, an RNN can attend over the output of another RNN. At every time step, it focuses on different positions in the other RNN.
神经网络也可以通过使用attention来实现类似的行为,专注于他们所给信息的子集的一部分。例如,一个RNN可以与另一个RNN的输出结果()。在每个时间step,它侧重于其他RNN中的不同位置。
We’d like attention to be differentiable, so that we can learn where to focus. To do this, we use the same trick Neural Turing Machines use: we focus everywhere, just to different extents.
我们希望attention是可以区分的,这样我们便可以学习在哪里集中注意力。要做到这一点,我们使用和神经图灵机想同的技巧:专注于各处,只是专注程度不同。
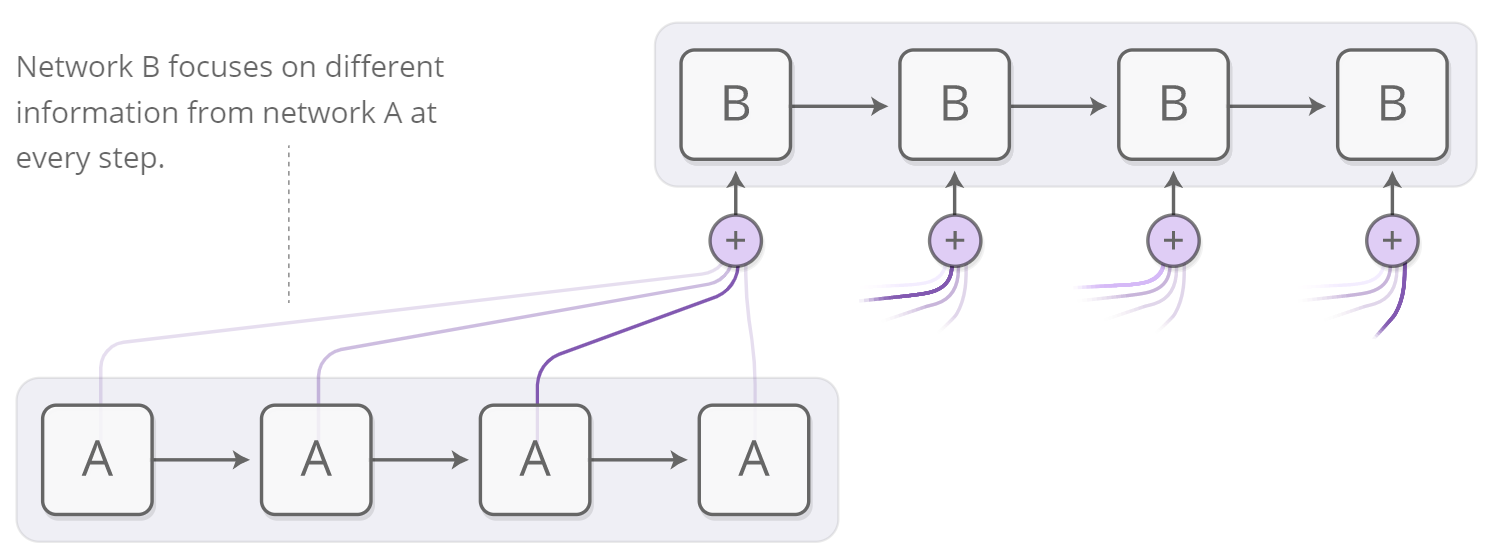
The attention distribution is usually generated with content-based attention. The attending RNN generates a query describing what it wants to focus on. Each item is dot-producted with the query to produce a score, describing how well it matches the query. The scores are fed into a softmax to create the attention distribution.
attention分布通常是通过基于内容的attention生成的。当前的RNN(比如B)会生成一项 描述其想要关注内容 的查询。其他的RNN(比如A)中每一项都会与该查询进行点乘,用于以生成 描述其与查询匹配程度的 得分。之后将该得分输入Softmax函数以生成注意力分布。

One use of attention between RNNs is translation [11]. A traditional sequence-to-sequence model has to boil the entire input down into a single vector and then expands it back out. Attention avoids this by allowing the RNN processing the input to pass along information about each word it sees, and then for the RNN generating the output to focus on words as they become relevant.
翻译是RNN间attention的用途之一[11]。传统的序列到序列模型必须将整个输入分解为单个向量,然后再将其扩展回来。Attention机制可通过允许RNN处理输入 来传递关于它看到的每个单词的信息 来避免这种情况,然后RNN生成输出 以在它们变得相关时关注单词。
](https://hexo-blog-1254804803.cos.ap-shanghai.myqcloud.com/img/attention3.png)
This kind of attention between RNNs has a number of other applications. It can be used in voice recognition [12], allowing one RNN to process the audio and then have another RNN skim over it, focusing on relevant parts as it generates a transcript.
RNN之间的这种attention还有很多其他应用。它可以用于语音识别[12],允许一个RNN来处理音频,然后让另一个RNN忽略它,在生成成绩单时仅关注相关部分。

Other uses of this kind of attention include parsing text [13], where it allows the model to glance at words as it generates the parse tree, and for conversational modeling [14], where it lets the model focus on previous parts of the conversation as it generates its response.
这种attention的其他用途包括文本解析[13],其中它允许模型在生成解析树时浏览单词;以及用于会话建模[14],其中在产生回应时,它使模型聚焦于对话的前面部分
Attention can also be used on the interface between a convolutional neural network and an RNN. This allows the RNN to look at different position of an image every step. One popular use of this kind of attention is for image captioning. First, a conv net processes the image, extracting high-level features. Then an RNN runs, generating a description of the image. As it generates each word in the description, the RNN focuses on the conv net’s interpretation of the relevant parts of the image. We can explicitly visualize this:
Attention也可以用在卷积神经网络和RNN之间的接口上。这允许RNN每一步都查看图像的不同位置。这种attention的一种流行用途是用于图像字幕。首先,一个conv网络处理图像,提取高阶特征;然后运行RNN,生成该图像的描述。当RNN生成描述中的每个单词时,RNN会聚焦于 conv网络对图像相关区域的解释。可视化如下:

More broadly, attentional interfaces can be used whenever one wants to interface with a neural network that has a repeating structure in its output.
更广泛的说,attention接口可以被用于任何 想到和一个输出中有重复架构的神经网络 交互的地方。
Attentional interfaces have been found to be an extremely general and powerful technique, and are becoming increasingly widespread.
Attention机制已经被证明是一件非常通用且功能强大的技术,并且正在变的越来越普遍。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!