MySQL实战45讲-下集(31-45)
本文最后更新于:2022年1月14日 晚上
33.我查这么多数据,会不会把数据库内存打爆?
由于MySQL是采取边读边发的逻辑,先一行行地读取数据存放在net_buffer中,存满了再调用网络接口发出去,因此MySQL 不会在server端存放完整的结果集,占用的MySQL内部内存最大也就是net_buffer_length(默认16K),因此一个大查询不会把内存打爆。但是,正因为是边读边发,如果客户端读结果不及时,会导致MySQL服务端由于结果发不出去,堵住查询过程…
而对于InnoDB引擎内部,由于有LRU算法之类的内存淘汰策略,及时清除InnoDB Buffer Pool中的旧数据,因此大查询也不会导致内存暴涨。并且,InnoDB对普通的LRU算法进行了改变,避免冷数据表全表查询时大量淘汰当前Buffer Pool里的数据导致内存命中率急剧下降、磁盘压力增加、SQL响应也变慢,InnoDB引擎按照5:3的比例将整个LRU链表分为young和old两个区域,① 需要插入新数据页时,不再放在链表头部,而是放在old区域头部;② 当访问已在LRU链表young区域中数据页时,将其移动到链表头部;③ 当访问在LRU链表old区域的数据页时,若这个数据页已在LRU链表中存在超过1s,将其移动到头部,未超过1s则保存位置不变。这样在全表扫描时,由于顺序数据页的多条记录,这个数据页第一次被访问和最后一次被访问的时间一般不超过1s,也就不会移动到young区域;又因为是冷数据表,后面继续扫描时也不会访问到了,慢慢地就被淘汰了…这样就使得大查询既利用了Buffer Pool,也不会对young区域和内存命中率造成恶劣的影响。
当然,全表扫描还是非常耗费IO资源的,所以业务高峰期尽量不要直接在线上主库执行全表扫描!

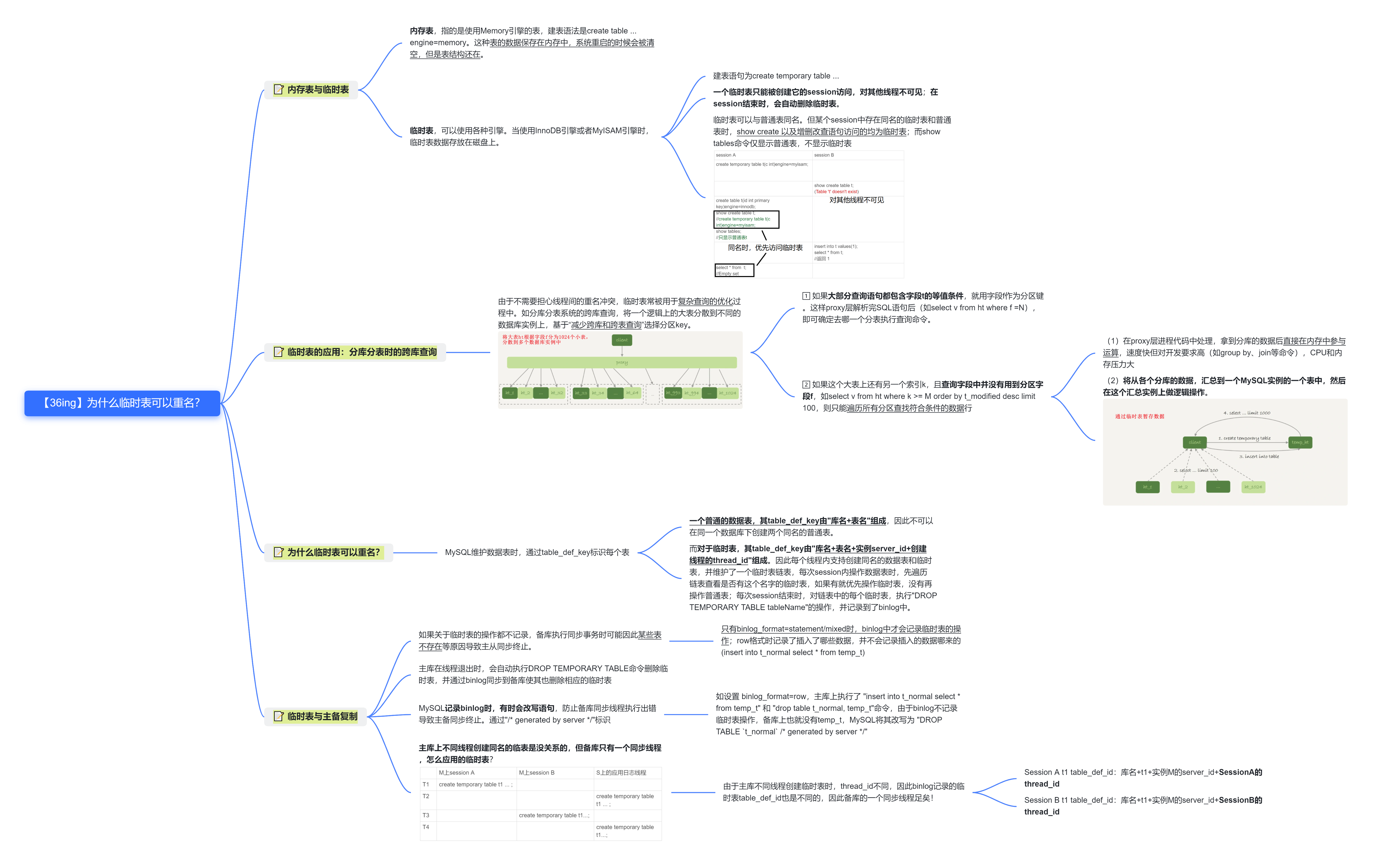
36.为什么临时表可以重名
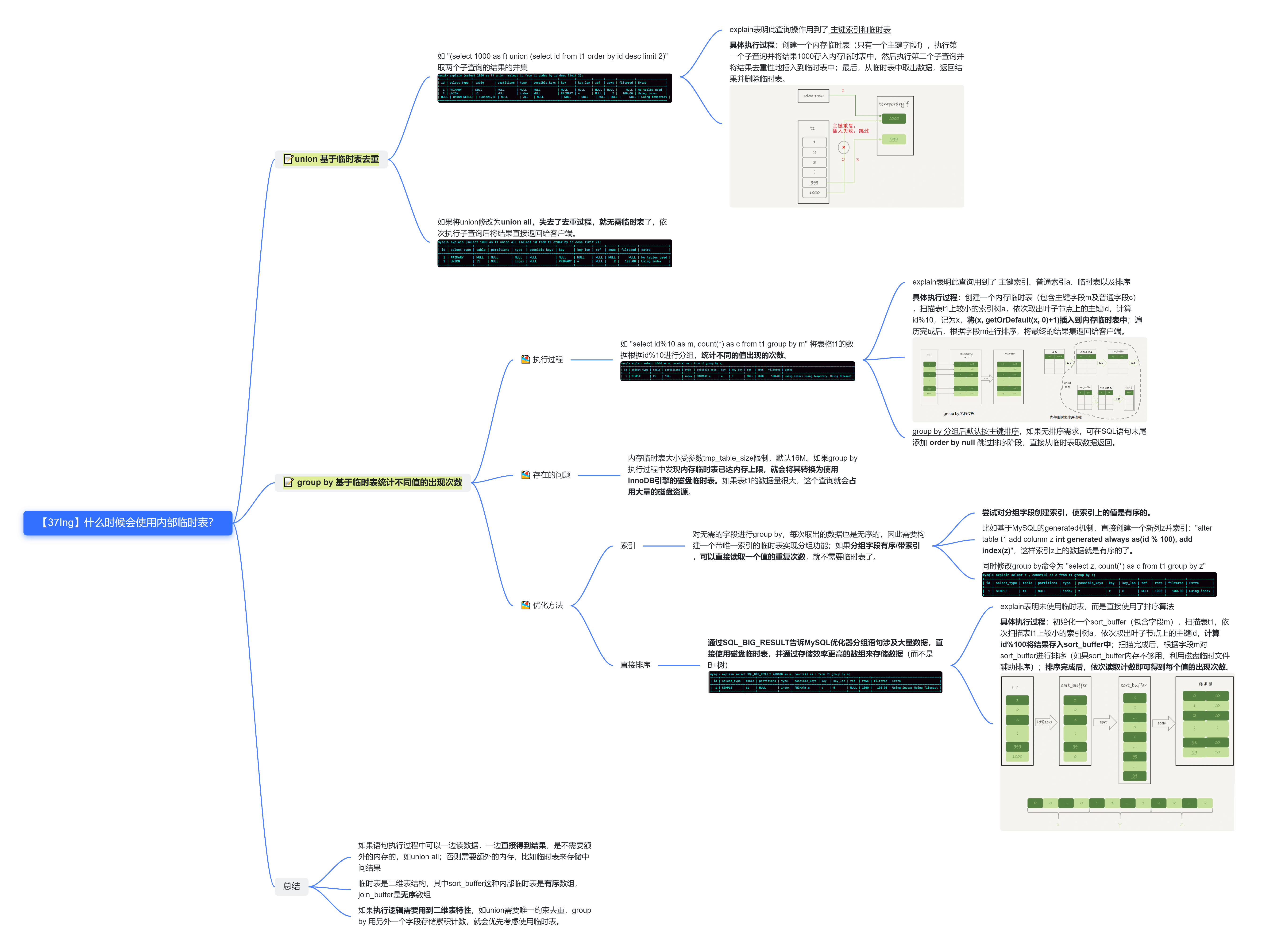
37.什么时候需要使用内部临时表
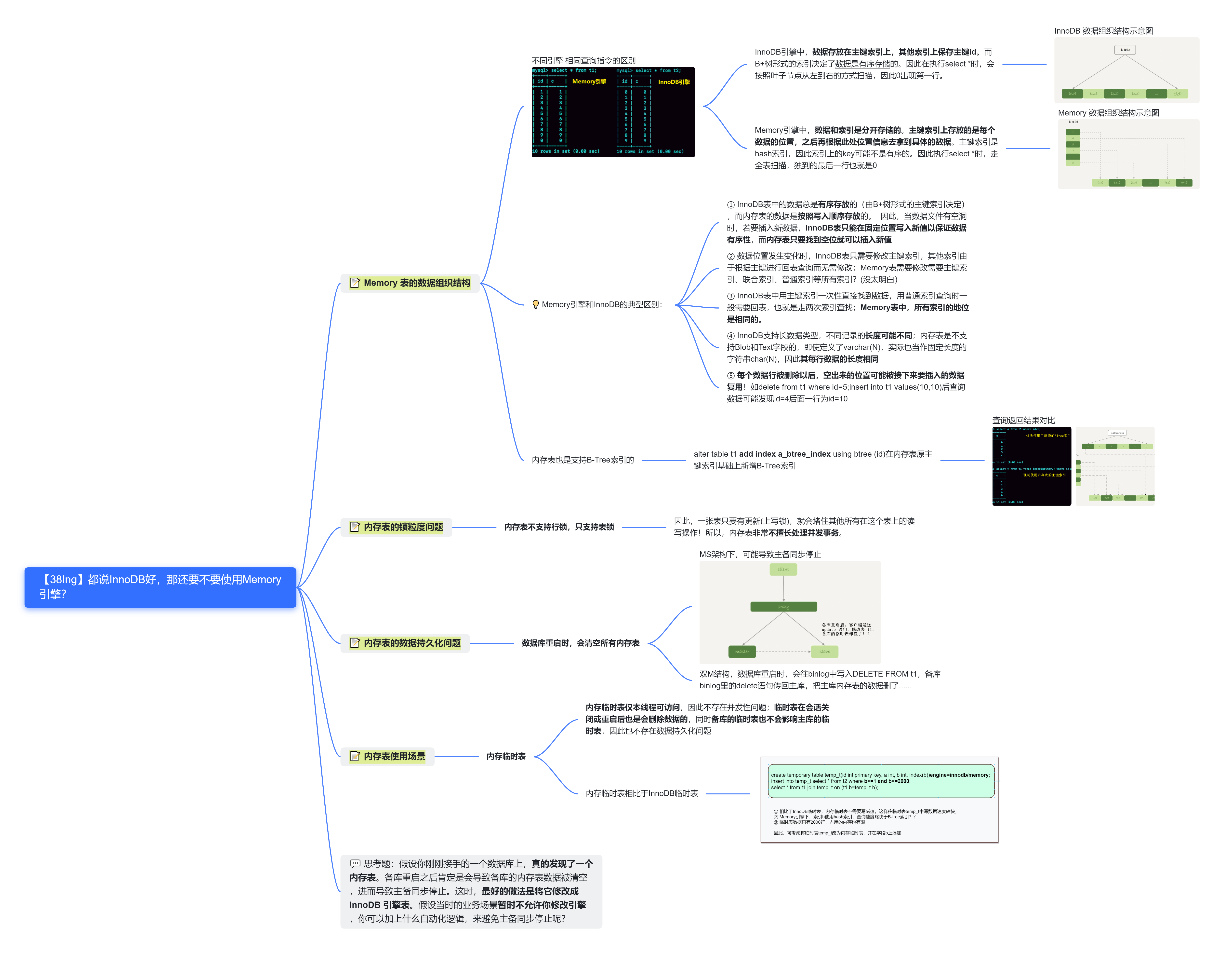
38.都是InnoDB引擎好,为什么还要用Memory引擎?
内存表由于支持hash索引,同时所有数据都保存在内存中,读写是明显快于磁盘表的。若因为内存表处理快而使用内存表,但能放到内存表中的数据一般不大,即使放在InnoDB中,数据缓存在InnoDB buffer pool里,性能也不会差!
此外,内存表仅支持行锁,不支持表锁。一张表在更新时,其他读写操作全部被堵住,并发性能有限。同时内存表存在持久化问题,即数据库重启时会情况所有内存表,这可能造成主备同步停止等问题。因此不建议在生产上使用普通内存表。
有一种场景,恰好可以忽略上面介绍的两个问题,使用Memory引擎建立表格,即内存临时表。内存临时表仅本线程可访问,因此不存在并发性问题;临时表在会话关闭或重启后也是会删除数据的,同时备库的临时表也不会影响主库的临时表,因此也不存在数据持久化问题。
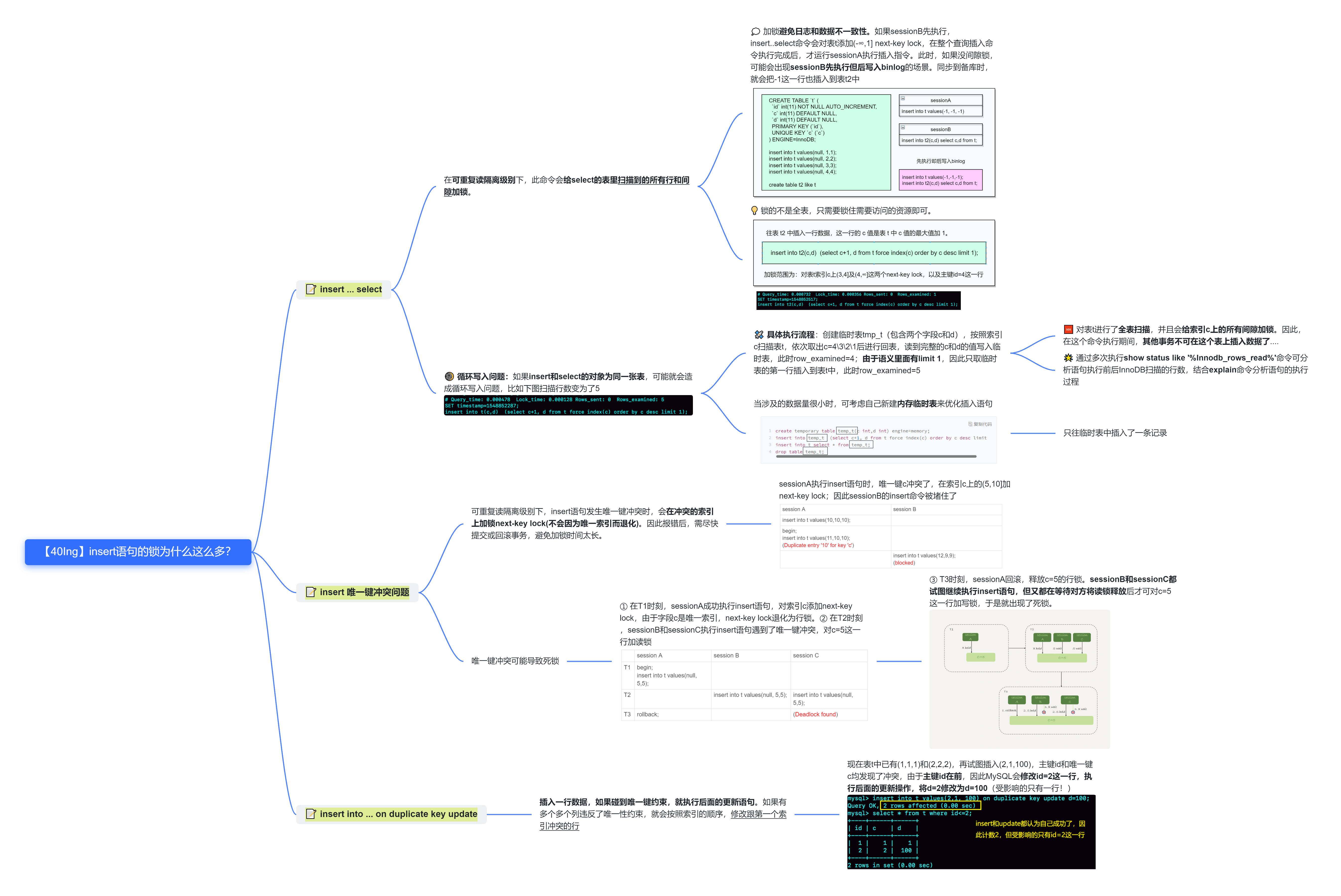
40.Insert语句的锁为什么这么多?
正常的insert语句执行完会添加next-key lock,如果遇到唯一索引,会退化为行锁;如果等值查询后的最后一个值不符合条件,退化为间隙锁。
insert ... select常用来在两个表之间拷贝数据,在可重复读隔离级别下,该命令会给select的表里扫描到的所有行的间隙加锁,以保证日志和数据的一致性。当select和insert操作的对象为同一张表时,可能存在循环写入问题,即select操作时可能对表进行了全表扫描,并将数据拷贝到了临时表中,操作比较冗余。如果涉及的数据量较小,可考虑新建用户临时表,来优化插入操作。
执行insert操作时,常遇到唯一键冲突问题。在可重复读隔离级别下,此时会对冲突的索引字段添加next-key lock(此场景下并不会因为唯一索引退化为行锁)。因此,程序报错后需要及时提交或回滚事务,避免加锁时间太长。此外,唯一键冲突时,有时会导致死锁。
相比于insert ... select命令,insert ... on duplicate key update ...命令在插入一行数据时,如果遇到唯一键冲突,不会报错,而是执行后面的更新操作。此时如果有多个列违反了唯一性约束,会优先修改跟第一个索引冲突的行!
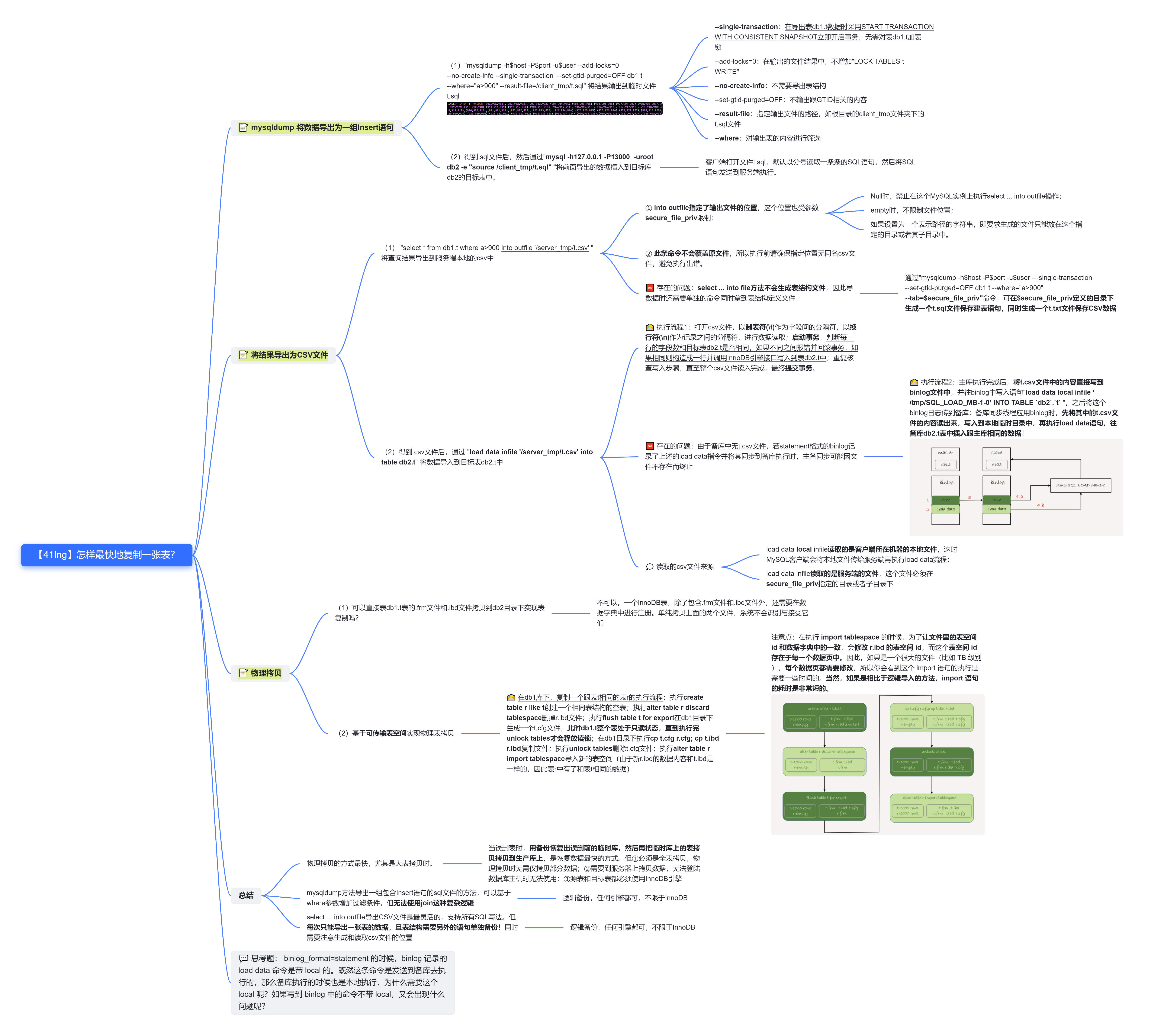
41.怎样最快地复制一张表?
- 通过
mysqldump导出包含一组INSERT命令的sql文件,然后通过source将数据导入到目标表中。可以基于where过滤数据,但无法使用join这种复杂逻辑 - 通过
select ... into outfile将查询结果导出到服务器本地的csv文件中,然后通过load data (local) infile导入数据。最灵活的一种方法,支持所有格式的SQL语法,但每次只能导出一张表格,但表结构需要另外的语句单独备份!同时需要注意生成和读取csv文件的路径,避免执行出错。 物理拷贝是三者中最快的复制方法,尤其是大表复制时。但必须是全表复制,不可仅拷贝部分数据;必须是InnoDB引擎的表,不支持Memory等引擎。
42.grant之后要跟着flush privileges命令吗
一般情况是不需要的。
- grant命令会同步修改数据表和内存,并在判断权限的时候使用内存数据。如果规范地使用grant和revoke语句,使内存权限数据和磁盘数据保存一致,也就无需flush privileges来清空内存acl_users数组等并基于现磁盘表重建内存中操作权限数据。
- 需要注意的一点是,grant修改db权限、表权限及列权限后,无需新建连接,会立刻感知到权限变化;而grant修改全局权限对于一个已经存在的连接是无效的,其基于新建连接时线程对象内部缓存的权限位进行权限校验,因此需要新建连接才可感知到权限变化。
- 有时直接使用DML语句操作系统权限表等不规范操作,会导致内存权限数据和磁盘表不一致。此时就需要flush privileges命令来重建内存权限数据了

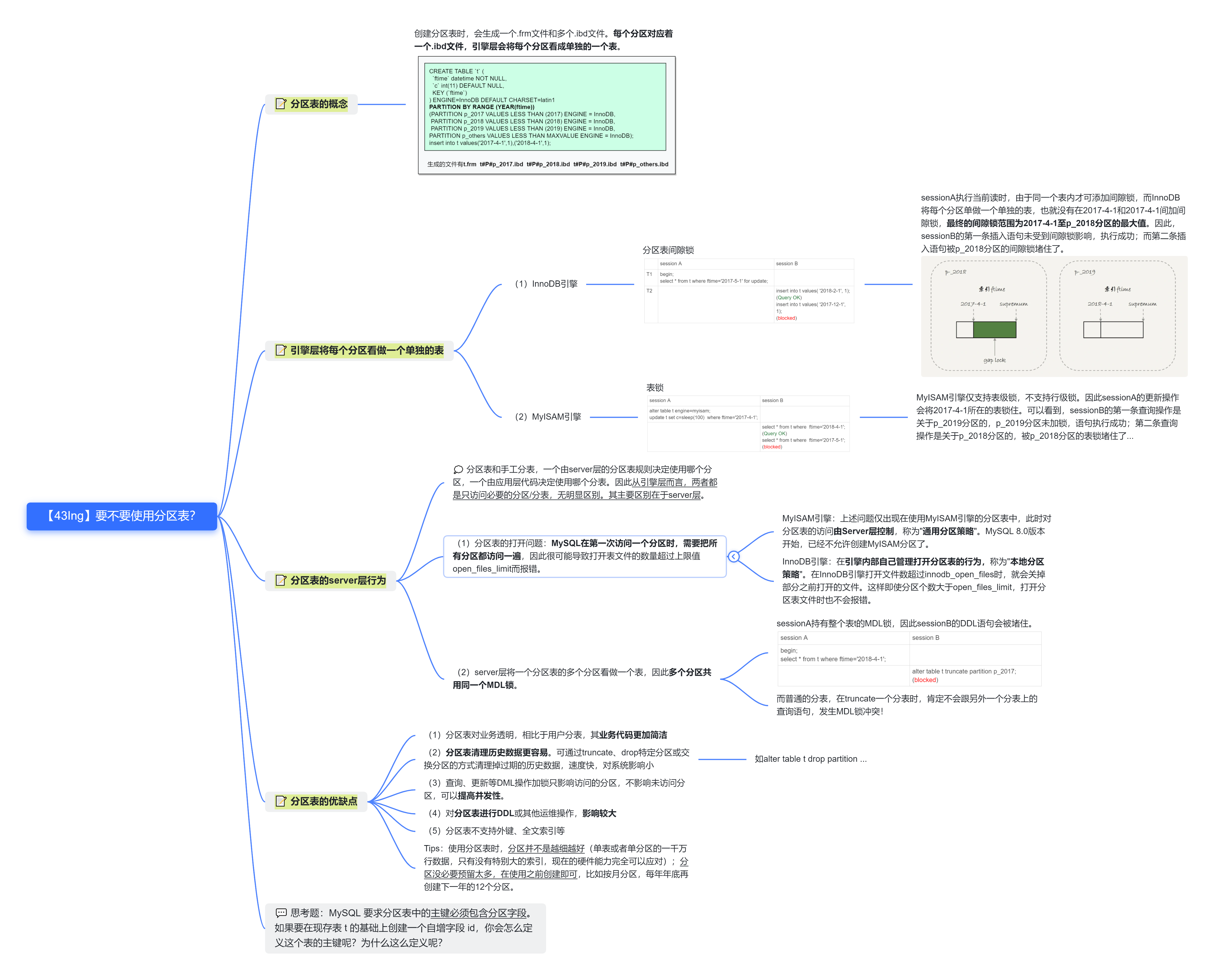
43.要不要使用临时表?
创建临时表时,会根据分区规则生成多个.ibd文件,每个.ibd文件对应着一个临时表分区。
分区表和手工分表,从引擎层而言,都是根据server层分区规则或应用层代码去访问必要的分区或分表,无明显差别。较小的一点不同为引擎层会把每个分区看做一个单独的表,在执行查询、更新等DML语句操作时,加锁只会影响访问到的分区,对未访问到的分区无影响,因此锁的细粒度可能略小于手工分表,并发性能略好些。
两者的主要区别在于server层,(1)分区表的打开问题。MySQL在第一次访问一个分区时,需要把所有分区都访问一遍。MyISAM引擎下可能会因此导致打开的表文件数量超出上限。而打开普通分表时无需打开其他分表,也就不存在这种问题。(2)server层将一个分区表的多个分区看做一个表,因此多个分区是公用同一个MDL锁的,从而导致对分区表进行DDL或其他运维操作,影响较大。而普通的分表,对其进行truncate等DDL操作是不会和其他分表上的查询语句,发送MDL锁冲突的。
临时表的优点主要在于对业务透明,相比于用户分表,业务代码更加简洁;此外,分区表清理历史数据也更容易些。可通过truncate、drop特定分区或交换分区的方式清理掉过期的历史数据,速度快,对系统影响小。
因此,还是需要根据具体的业务场景衡量临时表的优缺点,选择是否使用。
44.答疑文章
- join的写法:使用left join命令时,左侧的表不一定为驱动表,但join命令左侧的表一定为驱动表;如果要使用left join的语义输出驱动表的全部记录及被驱动表符合条件的记录,就不要将被驱动表的字段放在where条件里面进行判断,必须写在on里面。
- 相比于Block Nested Loop Join算法,Simple Nested Loop Join算法虽然同样进行了M*N次判断,但被驱动表进行了M次全表扫描(前者仅一次)。全表扫描时,将数据从磁盘读入内存会影响正常业务的Buffer Pool内存命中率,而多次全表扫描影响更甚;此外,进行记录匹配时,即使被驱动表数据都在记录中了,Simple Nested Loop Join算法在内存中寻找下一条记录的操作类似于指针遍历操作,是慢于Block Nested Loop Join算法的join_buffer数组的。因此,BNL算法的性能更加优异!
- 如果group by加了order by null,且无需返回不同值的出现次数count(*),其语义和执行流程是与distinct命令是完全相同的,因此性能也是相同的。

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!