Distilling Knowledge from Refinement in MLDN
本文最后更新于:2021年1月8日 晚上
摘要
基于MIL的弱监督目标检测方法通常从一组候选区域中选择得分最高的实例,然后再根据IoU取其相近区域。在本篇文章中,作者提出了一种自适应监督聚合函数(adaptive supervision aggregation function),可以动态地调整聚合标准,以选择与Ground Truth类别、背景甚至在生成每次优化模块监督时忽略的框。
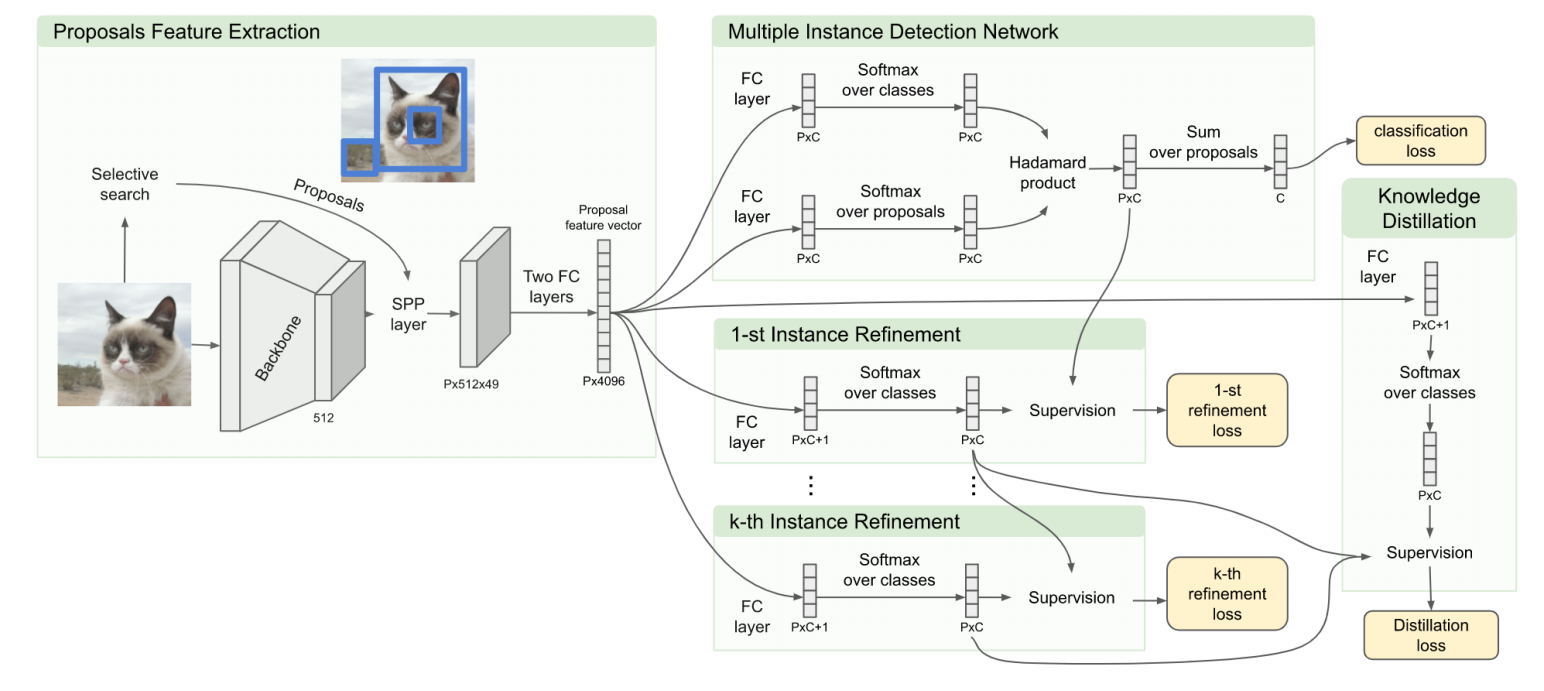
🔎 多实例学习模块
FC6、FC7后分为两个分支,分别接全连接层和Softmax得到预测得分,取两个分支预测得分的逐元素点乘获得该区域建议关于类别c的预测得分 即$x{cr}^R$,最后将所有区域建议预测得分求和,得到该图片关于类别c的预测得分$\phi{c}=\sum{r=1}^{|R|} \mathbf{x}{c r}^{R} \in(0,1)$,该模块采用多类别交叉熵损失函数来训练:
🍥 分类器优化模块
每级优化器由全连接层和Softmax组成,其中第k级的监督信息来自于k-1级,每个区域建议关于C+1个类别的监督(标注)信息为:
第k-1级优化器输出,对于类别c,先选取得分最高的区域建议,然后根据IOU选取与其相近的区域,标注为类别c,即$y{c j{c}^{k-1}}^{k}=1$,其他的标注为背景,即$y{c^{\prime} j{c}^{k-1}}^{k}=0, c^{\prime} \neq c$
损失函数为:
其中,$wr^k$用于抑制监督信息中的噪声,$w{r}^{k}=x{c j{c}^{k-1}}^{R k-1}$,即该区域建议在前一级关于类别c的预测得分

为了避免IoU阈值固定造成的信息丢失,作者们借鉴了C-MIL中提出的一种先递增后递减的损失函数:
其中,s表示当前训练次数,S为总共训练次数,$l_b$为常数(?)
此外,当图片中存在多个目标实例时,选取最高得分再取相近区域的方法会将其他的目标实例看做background

为了解决其他目标实例带来的损失,作者们引入了$\lambda_{ign}$来忽略和最高得分区域建议IoU贼小的区域建议,这样就可仅考虑上图中的红框为背景。
⏳ 知识蒸馏模块
第k级分类器的输出,只能用作第k+1级的监督,无法传递到第k+2级,这可能会损失部分信息。为了解决这个问题,作者们计划把所有优化模块的输出信息用作监督:
FC6、FC7后得到一组特征向量,维度为P×4096,将该特征向量经过一层全连接层,再经Softmax得到关于(C+1)个类别的预测得分向量:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!